1. 什么是MapReduce
1.1. MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发”基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2. MapReduce优点
易于编程
它简单的实现些接口,就可以完成个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写 —个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
高容错性
其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,完全是由Hadoop内部完成的
适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力
1.3. MapReduce缺点
不擅长实时计算
无法像Mysql一样,在毫秒或者秒级内返回结果
不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的
不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MaoReduce并不是不能做,而是使用后每个MapReduce作业的输出结果都会写入到磁盘,造成大量的磁盘IO,导致性能非常低下
2. MapReduce核心思想
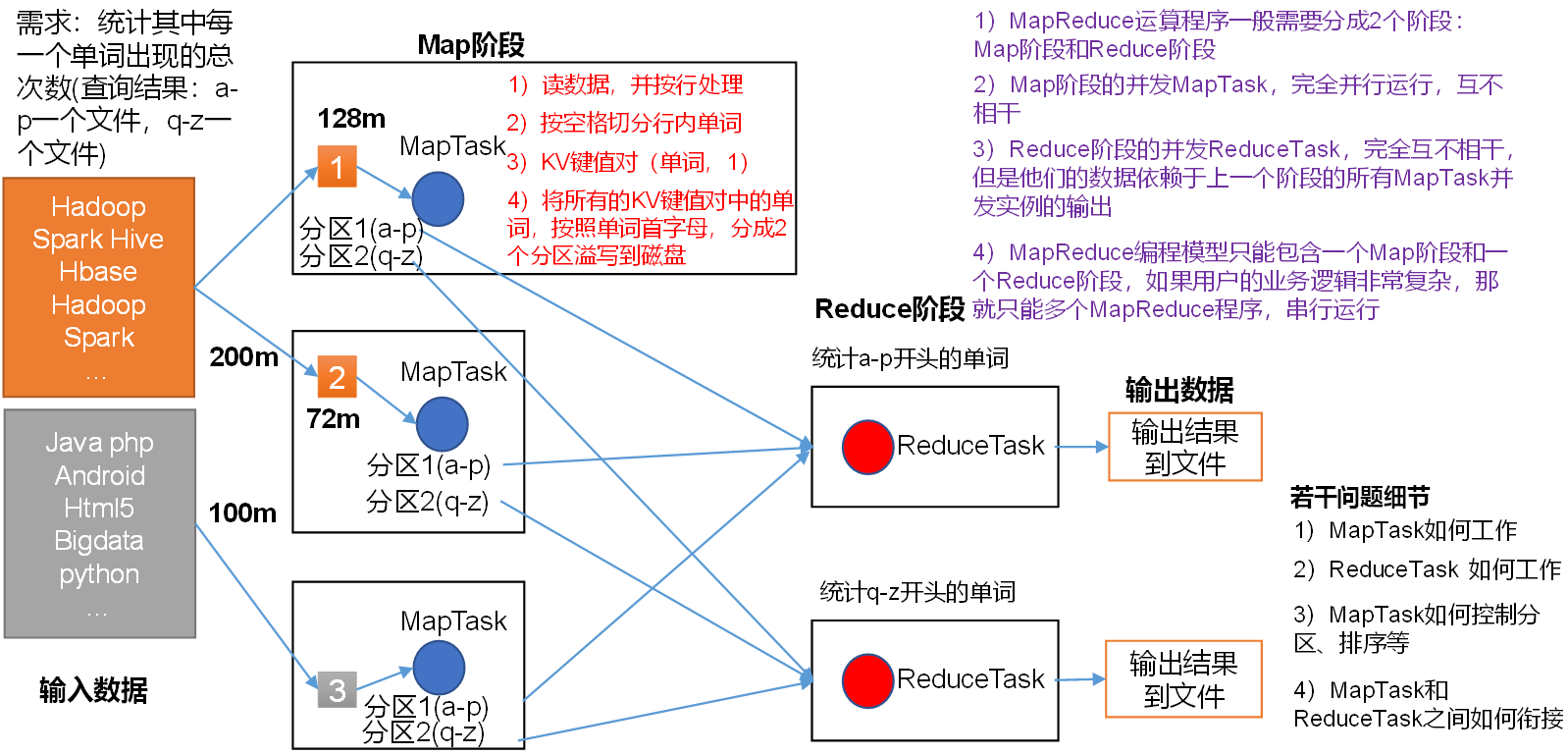
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
3. MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
1)MrAppMaster:负责整个程序的过程调度以及状态协调
2)MapTask:负责Map阶段的整个数据处理流程。即负责”分”
3)ReduceTask:负责Reduce阶段的整个数据处理流程。即负责”合”
MapReduce编程规范
用户编写程序分成三个部分:Mapper,Reducer 和 Driver
1)Mapper阶段
(1) 用户自定义Mapper要继承自己的父类
(2) Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3) Mapper中的业务逻辑写在map()方法中
(4) Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5) map()方法(MapTask进程)对每一个
2)Reducer阶段
(1) 用户自定义的Reducer要继承自己的父类
(2) Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3) Reducer的业务逻辑卸载reduce()方法中
(4) ReduceTask进程对每一组相同k的
3)Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
4. YARN架构

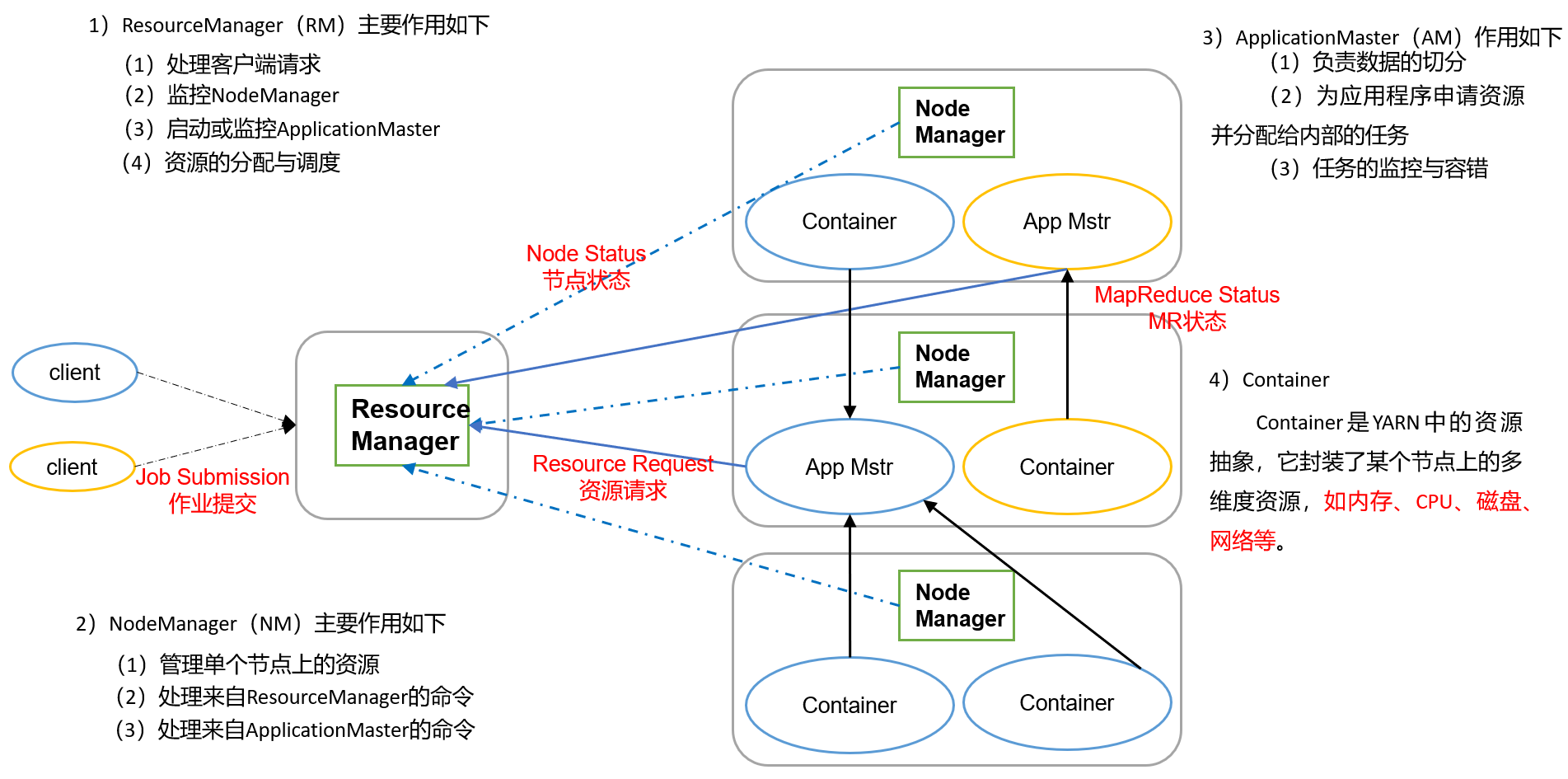
4.1. 各个组件的作用
ResourceManager
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
NodeManager
- 单个节点上的资源管理
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
ApplicationMaster
- 数据切分
- 为应用程序申请资源,并分配给内部任务
- 任务监控与容错
Container
- 对任务运行环境的抽象,封装了CPU内存等多维资源以及环境变量、启动命令等任务运 行相关的信息.
- Map、Reduce等任务都是运行在Container上
类比:
- ResourceManager:部门经理。整个集群资源的老大。
- NodeManager:项目组长。单个节点资源的老大。
- ApplicationMaster:项目经理。单个Job资源的老大。
- Container:组员。封闭资源信息。
4.2. ResourceManager
ResourceManager是全局的资源管理器,整个集群只有一个,负责集群资源的统一管理和调度分配。
4.2.1. ResourceManager的功能
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
4.3. NodeManager
NodeManager可以有多个节点,负责单个节点资源管理和使用
- NodeManager一般与DataNode在同一个节点
NodeManager的功能:
- 单个节点上的资源管理
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
NodeManager管理抽象容器Container,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源
NodeManager定时地向RM汇报节点上的资源使用情况和各个Container的运行状态
4.4. Application Master
管理一个在YARN内运行的应用程序的每个实例
功能:
- 数据切分
- 为应用程序申请资源,并分配给内部任务
- 任务监控与容错
负责协调来自ResourceManager的资源,开通过NodeManager监视容器的执行和资源使用(CPU,内存等的资源分配)
4.5. Container
YARN中的资源抽象,封装某个节点上多维度资源,如内存,CPU,自盘,网络等,当AM想RM申请资源时,RM向AM返回的资源便是用Container表示的
YARN 会为每个任务分配一个Container,且该任务只能使用Container中描述的资源
5. YARN 资源管理
资源调度和资源隔离是YARN作为一个资源管理系统,最重要和最基础的两个功能。
- 资源调度由ResourceManager完成
- 资源隔离由各个NodeManager实现
ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的”资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
当谈及到资源时,我们通常指内存,CPU和IO三种资源。Hadoop YARN同时支持内存和CPU两种资源的调度。
内存资源的多少会会决定任务的生死,如果内存不够,任务可能运行失败;相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的知识自己可以使用的,配置参数如下:
yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减这个值,而YARN不会只能的探测节点的物理内存总量。yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB).
目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算机能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可硬指定没干过任务需要的虚拟CPU个数。在YARN中,CPU相关配置参数如下:
yarn.nodemanager.resource.cpu-vcores
表示该节点上YANR可使用的虚拟CPU个数,默认是8,注意,目前推荐将该为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。yarn.scheduler.minimum-allocation-vcore
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最大虚拟CPU个数
6. MapReduce架构
离线计算框架 MapReduce
- 将计算过程分为两个阶段,map和reduce
- map 阶段并行处理输入数据
- reduce 阶段对map 结果进行汇总。
- shuffle 连接map 和Reduce 两个阶段
- map task 将数据写到本地磁盘
- reduce task 从每个map TASK 上读取一份数据
- 仅适合 离线批处理
- 具有很好的容错性和扩展性
- 适合简单的批处理任务
- 缺点明显
- 启动开销大,过多使用磁盘导致效率底下等。
7. MapReduce On YARN

- 客户端向YARN中提交应用程序/作业给ResourceManager,其中包括ApplicaitonMaster程序、启动ApplicationMaster的命令、用户程序等;
- ResourceManager为作业分配第一个Container,并与对应的NodeManager通信,要求它在这个Containter中启动该作业的ApplicationMaster(App Mstr);
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查询作业的运行状态;然后它将为各个任务申请资源并监控任务的运行状态,直到运行结束。即重复步骤4-7;
- ApplicationMaster采用轮询的方式通过RPC请求向ResourceManager申请和领取资源;
- 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务;
- 各个NodeManager分别在Container中启动Map任务(Map Task),或者启动Reduce任务(Reduce Task),或者都启动(如果本机资源足够的话);
- 各个任务通过RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicaitonMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
在作业运行过程中,用户可随时通过RPC向ApplicationMaster查询作业当前运行状态; - 作业完成后,ApplicationMaster向ResourceManager注销并关闭自己;
8. MapReduce各个阶段
MapReduce将计算过程分为两个阶段:Map(分)和Reduce(合)
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总


